In Operation#
Hopefully, you've got a provisioned server.
Do a quick check by ssh'ing to the server.
You should see a welcome message like:
This server is configured via Ansible.
Do not change configuration settings directly.
Admin email: steve@dcn.org
Custom Services/Ports
zeoserver: /usr/local/plone-5.0/zeoserver
/Plone: myhost [u'default']
zeo server: 127.0.0.1:8100
haproxy frontend: 8080
zeo clients: 127.0.0.1:8081 127.0.0.1:8082
haproxy monitor: 127.0.0.1:1080
varnish: 127.0.0.1:6081
varnish admin: 127.0.0.1:6082
postfix: 25 (host-only)
nginx:
- myhost: *:80
This gives you a list of all the long-lived services installed by the playbook and the interface/ports at which they're attached.
Note the service addresses which begin with 127.0.0.1.
Those services should only answer requests from the server itself: from the localhost.
See the firewalling section below for help on tightening this up.
How do you connect to local-only ports? Use SSH tunnels.
ssh ubuntu@54.244.201.44 -L 1080:localhost:1080 -L 6081:localhost:6081 -L 8080:localhost:8080
This is a pretty typical login that creates handy tunnels between ports on your local machine with matching HAProxy-admin, varnish and HAProxy frontend ports on the remote server.
While you're logged in, check out the status of the supervisor process-control system, which is used to launch your Zope/Plone processes.
sudo supervisorctl status
will list all the processes controlled by supervisor.
Plone Setup And Directories#
While you're logged in, let's take a look at the Plone/Zope setup.
You may modify the Zope/Plone directory layout created by the playbook.
Unless you do, the Playbook will put Plone's programs and configuration files in /usr/local by Plone version.
Data files will be in /var/local.
This split is intended to make it easier to organize backups and to put data on a different physical or logical device.
Unless you change it, backups are also under /var/local.
It's easy to change this, and it's not a bad idea to have backups on a different device.
In terms of file ownership and permissions, the Playbook pretty much follows the practices of the Plone Unified Installer.
Program and configuration files are owned by the plone_buildout user, and data, log and backup files are owned by the plone_daemon user.
A plone_group is used to give some needed communication, particularly the ability of buildout to create directories in the data space.
This means that if you need to run bin/buildout via login, it must be run as the plone_buildout user.
sudo -u plone_buildout bin/buildout
Typically, you would never start the main ZEO server or its clients directly. That's handled via supervisorctl.
There's one exception to this rule: the playbook creates a ZEO client named client_reserved that is not part of the load-balancer pool and is not managed by supervisor.
The purpose of this extra client is to allow you to handle run scripts or debug starts without affecting the load-balanced client pool. It's a good idea to use this mechanism to test an updated buildout:
sudo -u plone_daemon bin/client_reserved fg
Restart Script#
Still logged in? Let's take a look at another part of the install: the restart script.
Look in your buildout directory for the scripts directory.
In it, you should find restart_clients.sh.
(Go ahead and log out if you're still connected.)
This script, which needs to be run as the superuser via sudo, is intended to manage hot restarts. Its general strategy is to run through your ZEO clients, sequentially doing the following:
Mark it down for maintenance in HAProxy;
stop client;
start client; wait long enough for it to start listening
Fetch the homepage directly from the client to load the cache. This will be the first request the client receives, since HAProxy hasn't have marked it live yet. When HAProxy marks it live, the cache will be warm.
Mark the client available in HAProxy.
After running through the clients, it flushes the varnish cache.
This is useful if you're running multiple ZEO and using HAProxy for your load balancer.
Client Logs#
Unless you change it, the playbook sets up the clients to maintain 5 generations of event and access logs. Event logs are rotated at 5MB, access logs at 20MB.
Cron Jobs#
The playbook automatically creates cron jobs for ZODB backup and packing.
These jobs are run as plone_daemon.
The jobs are run in the early morning in the server's time zone. Backup is run daily; packing weekly.
Load Balancing#
Let's step up the delivery stack.
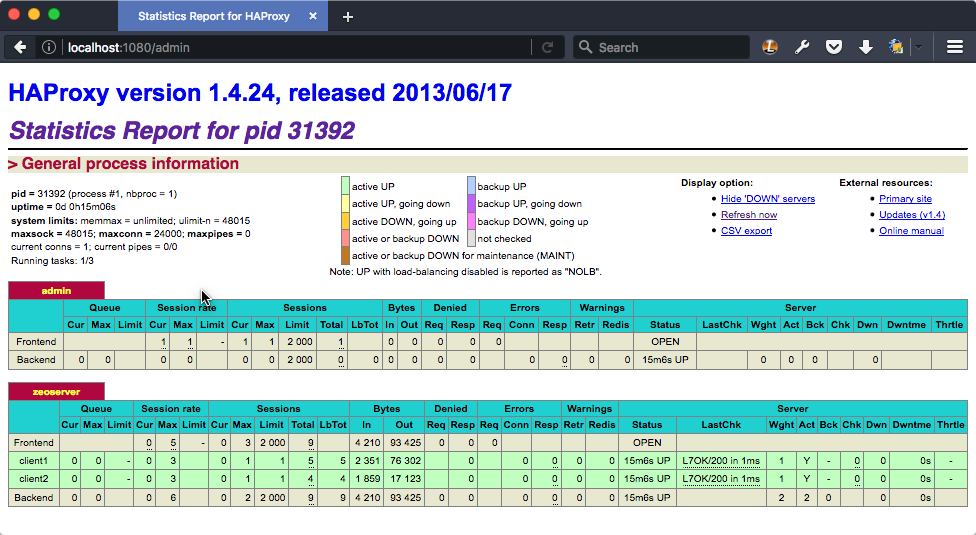
All but the smallest sample playbooks set up ZEO load balancing via HAProxy. One of the things we gain from HAProxy is good reporting.
The web interface for the HAProxy monitor is deliberately not available to a remote connection.
It's easy to get around that with an ssh tunnel:
ssh ubuntu@ourserver -L 1080:localhost:1080
Now we may ask for the web report at http://localhost:1080/admin.
Since we're restricting access, we don't bother with a password.
Haproxy monitor at http://localhost:1080/admin#
If your optimizing, it's a great idea to look at the HAProxy stats to see what kind of queues are building up in your ZEO client cluster.
A word about the cluster strategy.
We set up our clients with a single ZODB connection thread. There's a trade-off here.
Python's threading isn't great on multi-core machines. If you've got only one CPU core available, that's fine.
But modern servers typically have several cores; this scheme allows us to keep those cores more busy than they would be otherwise. The cost is somewhat more memory use: a ZEO client with multiple threads does some memory sharing between threads.
It's not a lot, but that gives it some memory use advantage over multiple, single-threaded clients. You may want to make that trade off differently.
We also have HAProxy set up to only make one connection at a time to each of our ZEO clients. This is also a trade off.
We lose the nice client behavior of automatically using different delivery threads for blobs.
But, we lower the risk that a request will sit for a long time in an individual client's queue (the client's connection queue, note haproxy's). If someone makes a request that will take several seconds to render and return, we'd like to avoid slowing down the response to other requests.
Reverse-proxy Caching#
We use Varnish for reverse-proxy caching. The size of the cache and its storage strategy is customizable.
By default, we set up 512MB caches.
That's probably about right if you're using a CDN (content delivery network), but may be low if if your site is large and you're not using a CDN.
The two small samples use Varnish's file method for cache storage.
The larger samples use malloc.
Varnish's control channel is limited to use by localhost and has no secret.
In a multi-Plone configuration, where you set up multiple, separate Plone servers with separate load-balancing frontends, our VCL setup does the dispatching to the different frontends.
Web Hosting#
We use Nginx for the outer web server, depending on it to do efficient URL rewriting for virtual hosting and for handling https.
We'll have much more to say about virtual hosting later when we talk about how to customize it.
What you need to know now is that simple virtual hosting is automatically set up between the hostname you supply in the inventory and the /Plone site in the ZODB.
You should be able to immediately ask for your server via http and get a Plone welcome page.
If your inventory hostname does not have a matching DNS host record, you're going to see something like:
Typical virtual hosting error.#
You're seeing a virtual-hosting setup error. The requested page is being returned, but all the resource URLs in the page -- images, style sheets and JavaScript resources -- are pointing to the hostname supplied in the inventory.
You may fix that by supplying a DNS-valid hostname, or by setting up specific virtual hosting. That's detailed below.
That's it for the delivery stack. Let's explore the other components installed by the playbook.
Postfix#
We use Postfix for our mailhost, and we set it up in a send-only configuration. In this configuration, it should not accept connections from the outside world.
Note
You will probably have another SMTP agent that's the real mail exchange (MX) for your domain.
Make sure that server is configured to accept mail from the FROM addresses in use on your Plone server.
Otherwise, mail exchanges that "grey list" may not accept mail from your Plone server.
Updating System Packages#
On Debian family Linux, the playbook sets up the server for automatic installation of routine updates. We do not set up an automatic reboot for updates that require a system restart.
Be aware that you'll need to watch for "reboot required" messages and schedule a reboot.
Fail2ban#
On Debian family Linux, the playbook installs fail2ban and configures it to temporarily block IP addresses that repeatedly fail login attempts via ssh.
Monitoring#
logwatch is installed and configured to email daily log summaries to the administrative email address.
Unless you prevent it, munin-node is installed and configured to accept connections from the IP address you designate. To make use of it, you'll need to install munin on a monitoring machine.
The munin-node install by the playbook disables many monitors that are unlikely to be useful to a mostly dedicated Plone servers. It also installs a Plone-specific monitor that reports resident memory usage by Plone components.
Changes Philosophy#
The general philosophy for playbook use is that you make all server configuration changes via Ansible. If you find yourself logging in to change settings, think again. That's the road to having a server that is no longer reproducible.
If you've got a significant change to make, try it first on a test server or a Vagrant box.
This does not mean that you'll never want to log into the server. It means that you shouldn't do it to change configuration.