Writing the Import Pipeline#
In this section you will:
Learn about the structure of the migration package
Learn the purpose of each step in the provided pipeline
Terminology#
- pipeline
The pipeline is a
.cfgfile, so the syntax will be familiar if you regularly edit your buildout.cfg. This file details the steps that each exported item takes during the import. All steps are looped over for each item in the import. Here is an example of a basic layout:[transmogrifier] pipeline = section_1 section_2 section_3 [section_1] blueprint = collective.transmogrifier.tests.examplesource size = 5 [section_2] blueprint = collective.transmogrifier.tests.exampletransform [section_3] blueprint = collective.transmogrifier.tests.exampleconstructor
- blueprint
Each step in the pipeline will specify a
blueprint. This is a Python class that determines how to handle the data for that step. There are many blueprints already available in the Transmogrifier add-ons, or you may need to write some blueprints to handle your custom content. Blueprints are specified byname, which is set in theconfigure.zcmlSee Writing Custom Blueprints for steps to set up your own.- item
The current piece of content in the loop being imported. When the importer first grabs the json data, it creates a dictionary called
item, that stores all the information from the json file. The pipeline can then manipulate the data in this dictionary, in order to prepare it for the actual import.
Here is a visualization of how the items move through the pipeline. Each item goes through each step of the pipeline, and each step points to some Python code that manipulates the item. A Plone object is created in the process, and saved in the site.
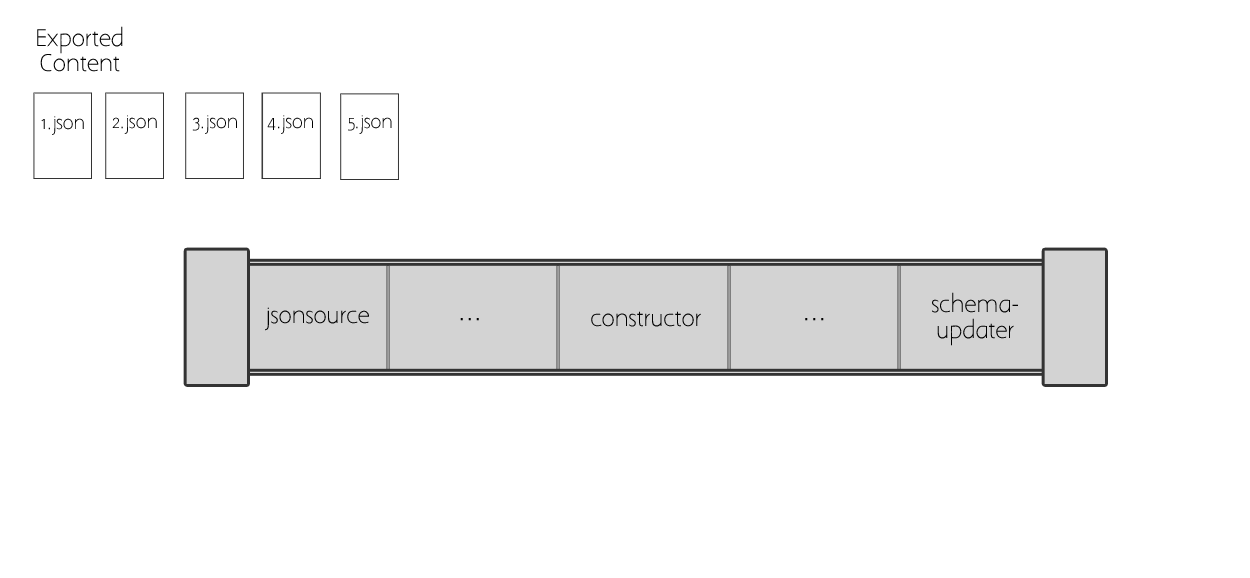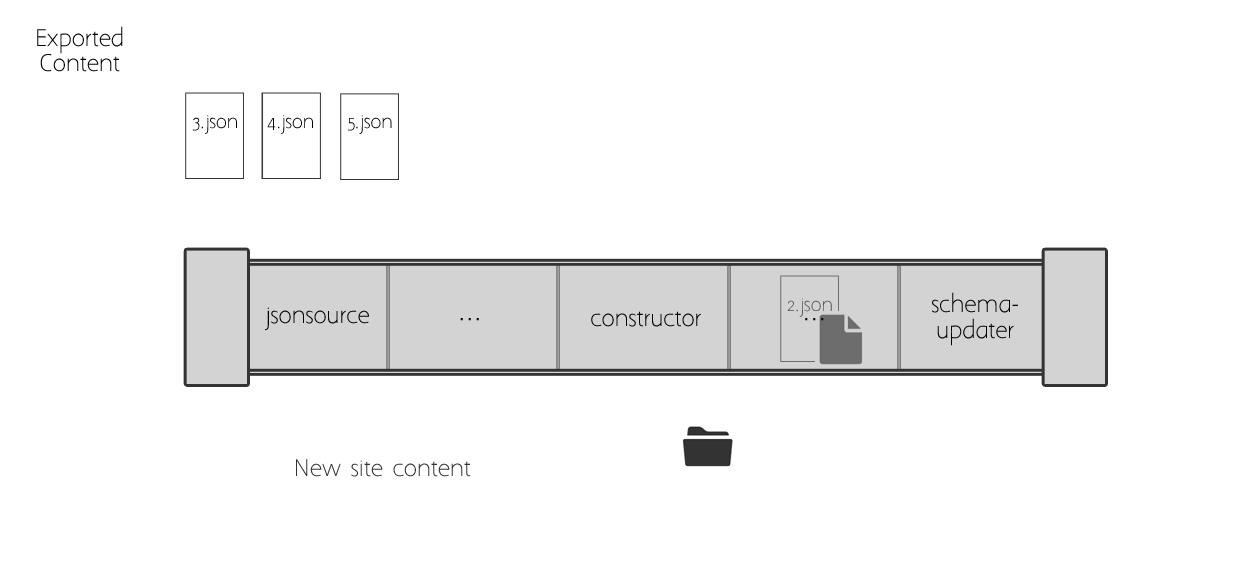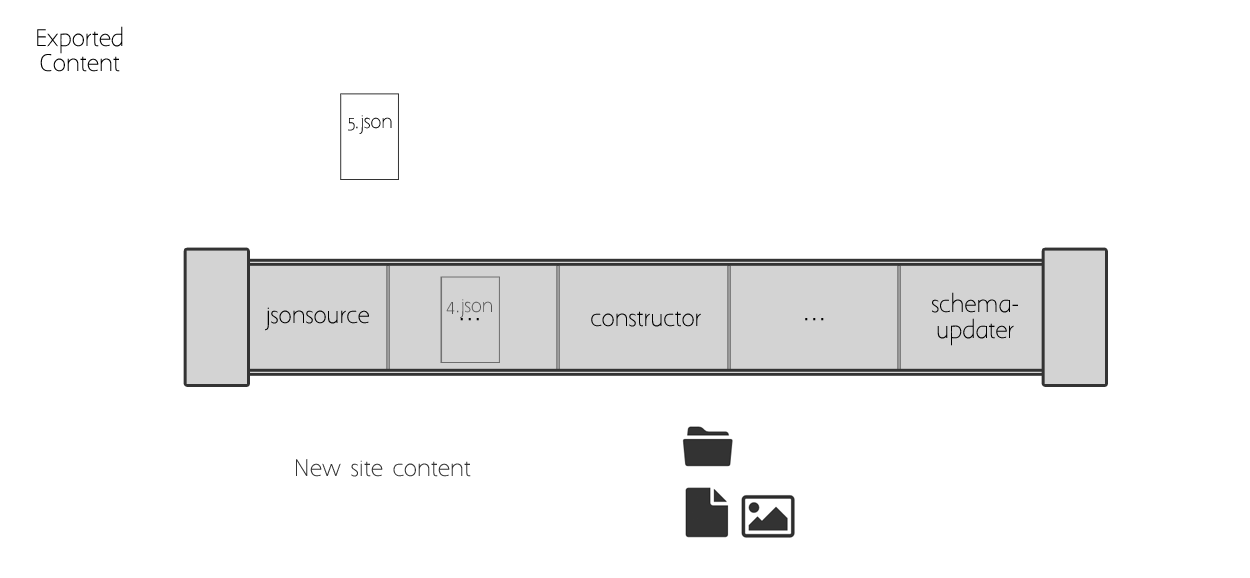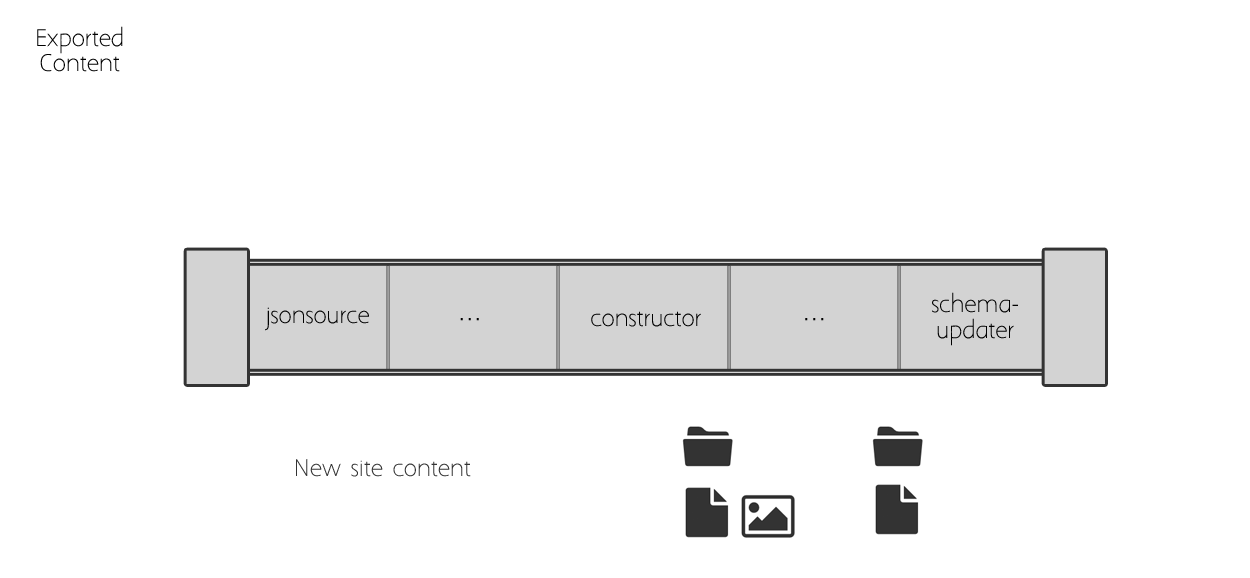
Pipeline Details#
Open the following file in your custom migration package: migration/import/import_content.cfg. By default, it contains the basic parts needed to migrate your content from a jsonify export. Unless your site is vanilla, out-of-the-box Plone and you want to migrate as-is, you'll likely need to customize this file.
First is the [transmogrifer] part which specifies the steps to run and their order.
The order is very important!
Each item in the import will run the steps in this order.
Each line corresponds to a part defined later in the file.
Comments can be added to this file by starting the line with #.
The most important pieces are jsonsource, constructor, and schemaupdater.
jsonsource needs to be the first step;
it specifies the local path to your exported content.
The path is relative to the root of the buildout.
If importing from a different type, such as CSV, there are blueprints that can handle this:
transmogrify.dexterity.csvimport and collective.transmogrifier.sections.csvsource.
The constructor creates an object in Plone for the current item in the import.
Any blueprints that manipulate the current item in the loop need to be in the pipeline before the constructor.
Once the object has been created in Plone, you can include blueprints after the constructor that manipulate that new object in Plone.
Then the schemaupdater migrates all the field and property data from the export to the new Plone object.
Other Included Pipeline Steps#
The other steps in the blueprint are included because they will likely be needed, but also to serve as examples.
Some steps only need to specify the blueprint, while others may require some additional parameters.
You can dig into the blueprint code to get a hint of what parameters might be required.
To add a new step, include its name in the top [transmogrifier] section,
then add the part later in the file. See Advanced Pipeline Tips for more information.
- logger
You get the option to output a line to the log for each item imported in the site. The
nameis prepended on to each log message.leveldetermines the log level. You can even have multiple loggers set to different levels, which would provide different output per environment. The provided sample will log the_pathfor each imported item.- pathfixer
The blueprint specified here is
plone.app.transmogrifier.pathfixer. When you open that file, you'll see thePathFixerclass:class PathFixer(object): """Changes the start of the path. """ classProvides(ISectionBlueprint) implements(ISection) def __init__(self, transmogrifier, name, options, previous): """ :param options['path-key']: The key, under the path can be found in the item. :param options['stripstring']: A string to strip from the beginning of the path. :param options['prependstring']: A string to prepend on the beginning of the path. """
This is useful for modifying and manipulating the start of each item's path, mainly used for the Plone site name. Items exported with jsonify include the Plone site name in the path. When you remove this, all items are imported at the root of the site instead of an extra level down. It is also helpful if you want to move content to be in a different folder.
- example
This is provided solely as an example to give you a starting point for making your own blueprint. It is currently commented out in the top
[transmogrifier]section, so it will not run until uncommented. The blueprint name,mysite.exampleis defined in the configure.zcml, where it points to the Python Class. See Writing Custom Blueprints for more information about writing custom blueprints.- removeid
The removeid step is fairly straightforward, it removes the
idkey from the item. If theidis left in, objects aren't properly created in the Plone site. Instead, the id for the object will be pulled from the_path.- copyuid
This part uses the
manipulatorblueprint, and allows you to copy a key from the item to the Plone object using a TALES expression. Thecopyuidpart is needed for theschemaupdaterto properly set the item's UUID.- deserializer
If the data was contained inside of an attached JSON file, push that data back into the pipeline for the next step.
- workflowhistory
The workflowhistory step will put all your newly imported content into the same review state it was in on the old site.
- savepoint
For large sites, you may have thousands of items being imported, and it can be a pain to start over when you hit an error. The example
savepointwill commit after every 1000 items. This is set to 1000, because a jsonify export saves 1000 items to a folder. This will be discussed more later in Running the Content Import. You can adjust to save how often you want.
New Pipeline Step#
Let's add a new pipeline step that will fix the language of the imported items.
If you look at a couple pieces of content in the export, you will see:
"language": "en",
This may cause a problem on import, because Plone 5 will default to the language as "en-us". Or it will be a problem if you set a different language as the default. So let's add a custom pipeline step to fix this.
First determine where the new step should appear in the pipeline.
We want to manipulate the value stored in the item dictionary,
before an object is created in the site.
So let's put the step before the constructor:
[transmogrifier]
pipeline =
jsonsource
logger
pathfixer
setlanguage
# ...
Then further down in the file, add the setlanguage part with the following code:
[setlanguage]
blueprint = collective.transmogrifier.sections.inserter
key = string:language
value = string:en-us
This will take the language key from the item dictionary,
and change the value to whatever we set,
in this case it will be the string en-us.
Your value may be different, depending on what language you set as your site language.
Check the control panel to see what value you should use.